TOON - The New JSON
JSON is everywhere. APIs use it. So do backends and frontends. It is the basic and the default way most of the services talk.
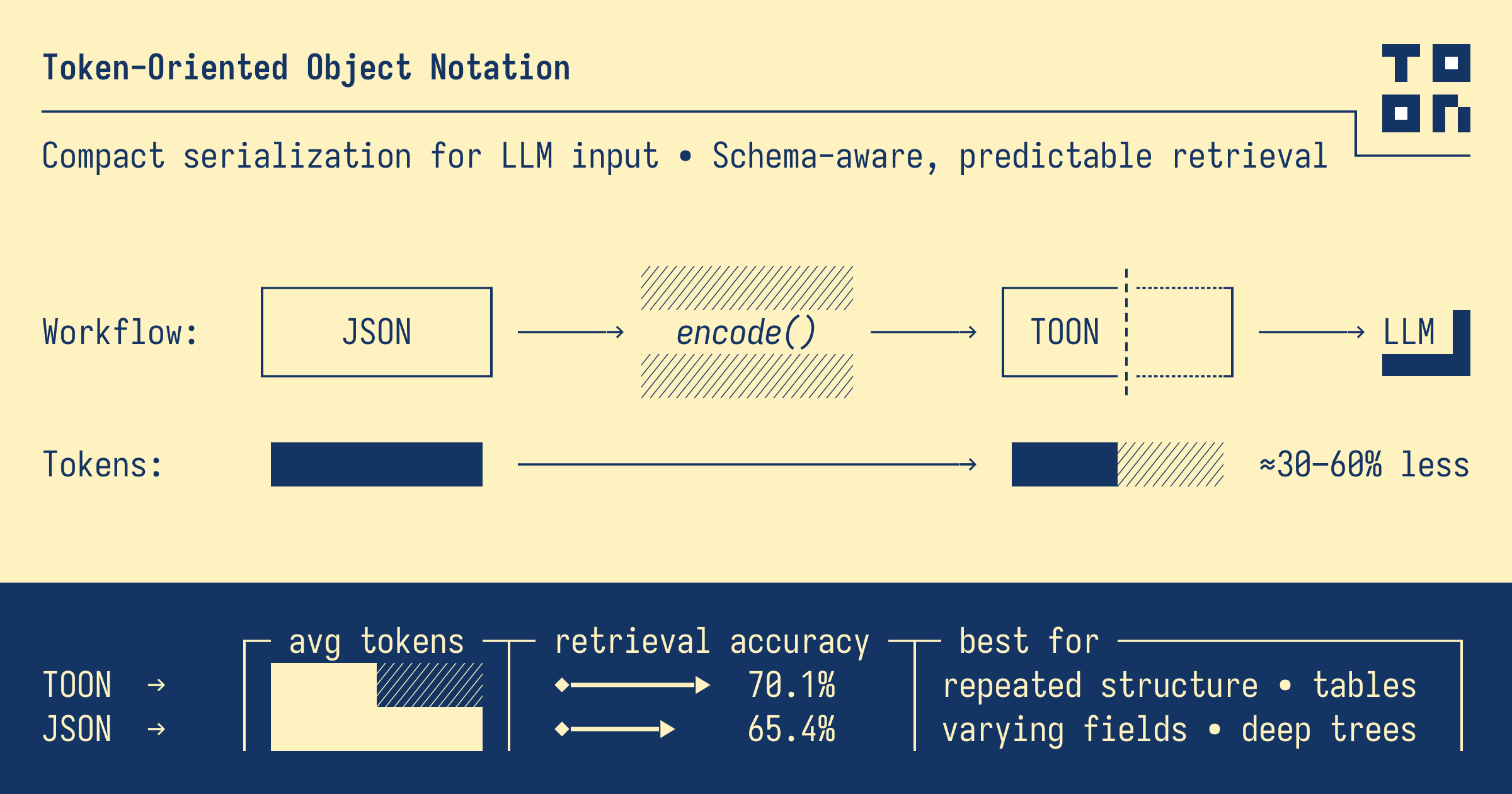
But JSON wasn’t made for large language models. It carries a lot of unnecessary baggage: curly braces, commas, extra spaces. All those were required for programmatic purposes, proper formatted so that it could be indexed properly, parsed properly, read properly & play with all the kinds of logic we want. It help human eyes and programs, but for models they just take up too much tokens.
And the problem is when you send JSON to an LLM, every character is a token. Each bracket be in starting-ending, each newline, each comma adds to your token count. That means higher cost, higher processing time, higher CO2 consumption and what not.
Taking this as an example:
|
|
The data’s clear, but the format is heavy, redundant characters are too much. For models, all the extras waste tokens.
And now what TOON (Token-Oriented Object Notation) does is, it just strips out what large language models don’t need, unnecessary curly braces, commas, extra spaces. It just keeps the data, drops the noise.
Like this:
user_id:123,email:[email protected],active:true
With this you allegedly reduce 40-60% of the tokens. Things run faster. It costs less to process, keeps your pocket warm & also CO2 control, much needed one.
But the problem is, TOON works best on flat JSON data. If your JSON is nested—one object inside another—flatten it first. If you don’t, TOON can make things worse. You’ll use more tokens; likely 20-30% more, not fewer.
So, we have turn this (Nested JSON):
|
|
To this (Flat Normalized JSON):
|
|
You can make use of JSON normalizer packages if available for the respective programming languages. Then only, the TOON gives you the benefit.
Thus, we have to make use of TOON when it fits:
- JSON is flat or you can flatten it, either manually or via normalizers.
- Token costs matter.
- You’re optimizing for models—not humans.
And hence, If you are in need of human readability, stick with JSON. If your JSON structure is deeply nested and you can’t flatten it due to some complexities, TOON may not help.
Which is why it asks us to measure the difference and then only test on our own data or make use of it.
The point is simple. Better performance, lower cost, less waste. No drama. No buzzwords.
And that’s how we tune and optimize systems to run and not just compile go, not knowing if it is the function or the disease running it.
Know more in detail: TOON Github